Factorization Machines
Jefkine, 27 March 2017Introduction
Factorization machines were first introduced by Steffen Rendle [1] in 2010. The idea behind FMs is to model interactions between features (explanatory variables) using factorized parameters. The FM model has the ability to the estimate all interactions between features even with extreme sparsity of data.
FMs are generic in the sense that they can mimic many different factorization models just by feature engineering. For this reason FMs combine the high-prediction accuracy of factorization models with the flexibility of feature engineering.
From Polynomial Regression to Factorization Machines
In order for a recommender system to make predictions it relies on available data generated from recording of significant user events. These are records of transactions which indicate strong interest and intent for instance: downloads, purchases, ratings.
For a movie review system which records as transaction data; what rating is given to a movie (item) by a user at a certain time of rating , the resulting dataset could be depicted as follows:
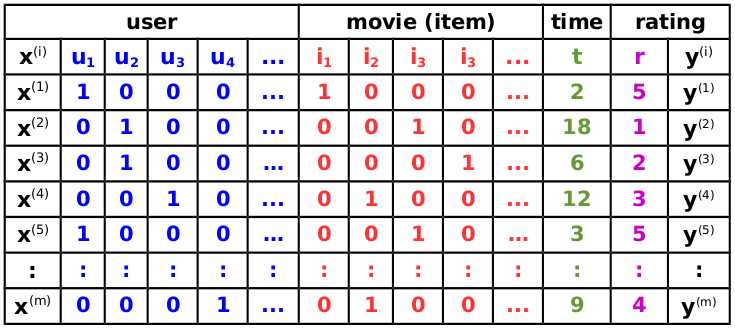
If we model this as a regression problem, the data used for prediction is represented by a design matrix consisting of a total of observations each made up of real valued feature vector . A feature vector from the above dataset could be represented as:
where i.e is also represented as
This results in a supervised setting where the training dataset is organised in the form . Our task is to estimate a function which when provided with row as the input to can correctly predict the corresponding target .
Using linear regression as our model function we have the following:
Parameters to be learned from the training data
- is the global bias
- are the weights for feature vector
With three categorical variables: user , movie (item) , and time , applying linear regression model to this data leads to:
This model works well and among others has the following advantages:
- Can be computed in linear time
- Learning can be cast as a convex optimization problem
The major drawback with this model is that it does not handle feature interactions. The three categorical variables are learned or weighted individually. We cannot therefore capture interactions such as which user likes or dislikes which movie (item) based on the rating they give.
To capture this interaction, we could introduce a weight that combines both user and movie (item) interaction i.e .
An order polynomial has the ability to learn a weight for each feature combination. The resulting model is shown below:
Parameters to be learned from the training data
- is the global bias
- are the weights for feature vector
- is the weight matrix for feature vector combination
With three categorical variables: user , movie (item) , and time , applying order polynomial regression model to this data leads to:
This model is an improvement over our previous model and among others has the following advantages:
- Can capture feature interactions at least for two features at a time
- Learning and can be cast as a convex optimization problem
Even with these notable improvements over the previous model, we still are faced with some challenges including the fact that we have now ended up with a complexity which means that to train the model we now require more time and memory.
A key point to note is that in most cases, datasets from recommendation systems are mostly sparse and this will adversely affect the ability to learn as it depends on the feature interactions being explicitly recorded in the available dataset. From the sparse dataset, we cannot obtain enough samples of the feature interactions needed to learn .
The standard polynomial regression model suffers from the fact that feature interactions have to be modeled by an independent parameter . Factorization machines on the other hand ensure that all interactions between pairs of features are modeled using factorized interaction parameters.
The FM model of order is defined as follows:
is the dot product of two feature vectors of size :
This means that Eq. can be written as:
Parameters to be learned from the training data
- is the global bias
- are the weights for feature vector
- is the weight matrix for feature vector combination
With three categorical variables: user , movie (item) , and time , applying factorization machines model to this data leads to:
The FM model replaces feature combination weights with factorized interaction parameters between pairs such that .
Any positive semi-definite matrix can be decomposed into (e.g., Cholesky Decomposition). The FM model can express any pairwise interaction matrix provided that the chosen is reasonably large enough. where is a hyper-parameter that defines the rank of the factorization.
The problem of sparsity nonetheless implies that the chosen should be small as there is not enough data to estimate complex interactions . Unlike in polynomial regression we cannot use the full matrix to model interactions.
FMs learn in factorized form hence the number of parameters to be estimated is reduced from to since . This reduces overfitting and produces improved interaction matrices leading to better prediction under sparsity.
The FM model equation in Eq. now requires because all pairwise interactions have to be computed. This is an increase over the required in the polynomial regression implementation in Eq. .
With some reformulation however, we can reduce the complexity from to a linear time complexity as shown below:
The positive semi-definite matrix which contains the weights of pairwise feature interactions is symmetric. With symmetry, summing over different pairs is the same as summing over all pairs minus the self-interactions (divided by two). This is the reason why the value is introduced as from Eq. and beyond.
Let us use some images to expound on this equations even further. For our purposes we will use a symmetric matrix from which we are expecting to end up with as follows:
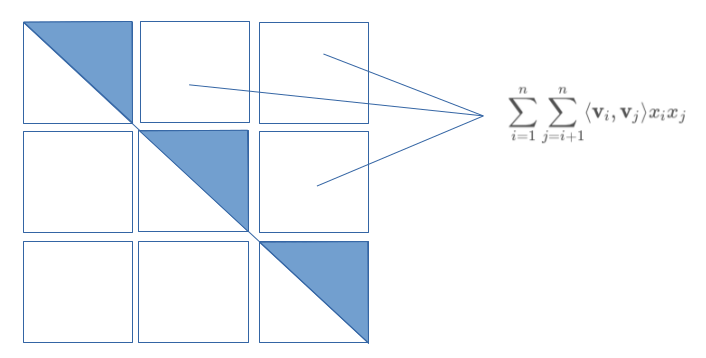
The first part of the Eq. marked represents a half of the symmetric matrix as shown below:
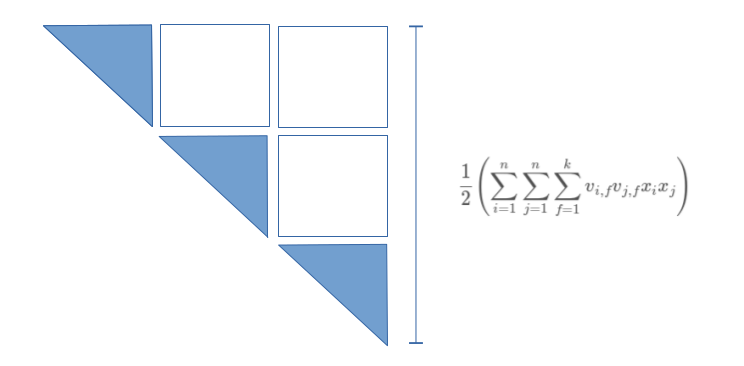
To end up with our intended summation , we will have to reduce the summation shown above with the second part of Eq. marked as follows:
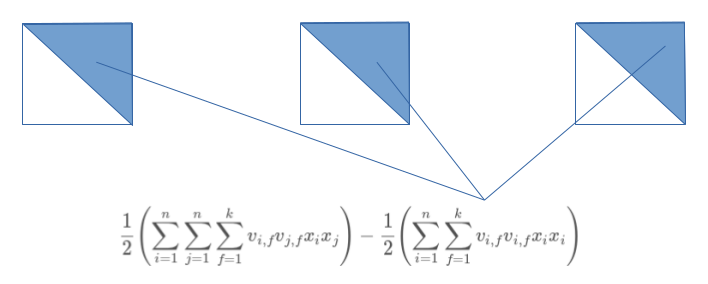
Substistuting Eq. in Eq. we end up with an equation of the form:
Eq. now has linear complexity in both and . The computation complexity here is .
For real world problems most of the elements in the feature vector are zeros. With this in mind lets go ahead and define some two quantities here:
- - the number of non-zero elements in feature vector
- - the average number of none-zero elements of all vectors (average for the whole dataset or the number of non-zero elements in the design matrix )
From our previous equations it is easy to see that the numerous zero values in the feature vectors will only leave us with non zero values to work with in the summation (sums over ) on Eq. where . This means that our complexity will drop down even further from to .
This can be seen as a much needed improvement over polynomial regression with the computation complexity of .
Learning Factorization Machines
FMs have a closed model equation which can be computed in linear time. Three learning methods prposed in [2] are stochastic gradient descent(SGD), alternating least squares (ALS) and Markov Chain Monte Carlo (MCMC) inference.
The model parameters to be learned are and . The loss function chosen will depend on the task at hand. For example:
- For regression, we use least square loss:
- For binary classification, we use logit or hinge loss: where is the sigmoid/logistic function and .
FMs are prone to overfitting and for this reason regularization is applied. Finally, the gradients of the model equation for FMs can be depicted as follows:
Notice that the sum is independent of and thus can be precomputed. Each gradient can be computed in constant time and all parameter updates for a case can be done in or under sparsity.
For a total of iterations all the proposed learning algorithms can be said to have a runtime of .
Conclusions
FMs also feature some notable improvements over other models including
- FMs model equation can be computed in linear time leading to fast computation of the model
- FM models can work with any real valued feature vector as input unlike other models that work with restricted input data
- FMs allow for parameter estimation even under very sparse data
- Factorization of parameters allows for estimation of higher order interaction effects even if no observations for the interactions are available