Vanishing And Exploding Gradient Problems
Jefkine, 21 May 2018Introduction
Two of the common problems associated with training of deep neural networks using gradient-based learning methods and backpropagation include the vanishing gradients and that of the exploding gradients.
In this article we explore how these problems affect the training of recurrent neural networks and also explore some of the methods that have been proposed as solutions.
Recurrent Neural Network
A recurrent neural network has the structure of multiple feedforward neural networks with connections among their hidden units. Each layer on the RNN represents a distinct time step and the weights are shared across time.
The combined feedfoward neural networks work over time to compute parts of the output one at a time sequentially.
Connections among the hidden units allow the model to iteratively build a relevant summary of past observations hence capturing dependencies between events that are several steps apart in the data.
An illustration of the RNN model is given below:
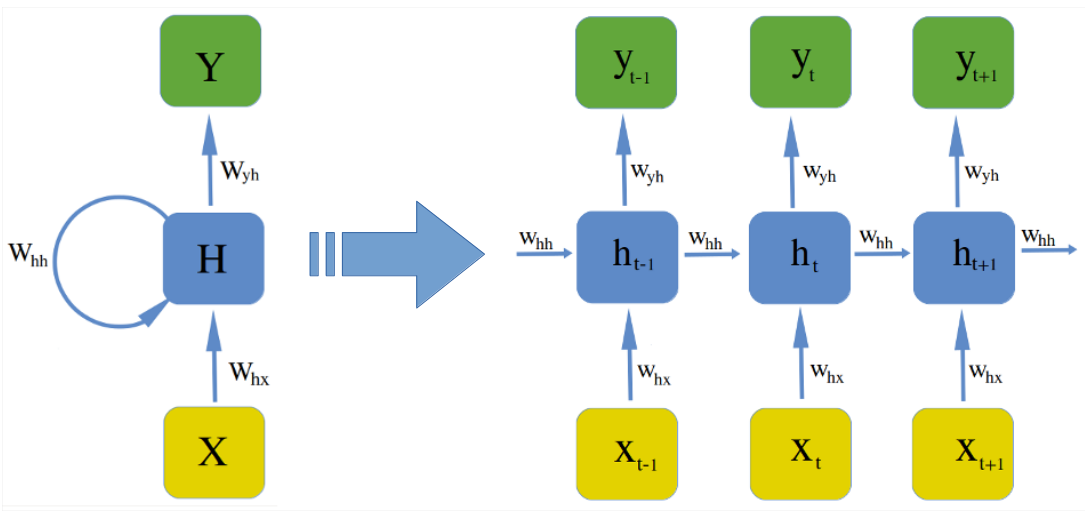
For any given time point , the hidden state is computed using a function with parameters that takes in the current data point and hidden state in the previous time point . i.e .
represents a set of tunable parameters or weights on which the function depends. Note that the same weight matrix and function are used at every timestep.
Parameters control what will be remembered and what will be discarded about the past sequence allowing data points from the past say for to influence the current and even later outputs by way of the recurrent connections
In its functional form, the recurrent neural network can be represented as:
From the above equations we can see that the RNN model is parameterized by three weight matrices
- is the weight matrix between input and the hidden layer
- is the weight matrix between two hidden layers
- is the weight matrix between the hidden layer and the output
We also have bias vectors incorporated into the model as well
- is the bias vector added to the hidden layer
- is the bias vector added to the output layer
is the non-linearity added to the hidden states while is the activation function used in the output layer.
RNNs are trained in a sequential supervised manner. For time step , the error is given by the difference between the predicted and targeted: . The overall loss is usually a sum of time step specific losses found in the range of intrest given by:
Vanishing and Exploding Gradients
Training of the unfolded recurrent neural network is done across multiple time steps using backpropagation where the overall error gradient is equal to the sum of the individual error gradients at each time step.
This algorithm is known as backpropagation through time (BPTT). If we take a total of time steps, the error is given by the following equation:
Applying chain rule to compute the overall error gradient we have the following
The term marked ie is the derivative of the hidden state at time with respect to the hidden state at time . This term involves products of Jacobians over subsequences linking an event at time and one at time given by:
The product of Jacobians in Eq. features the derivative of the term w.r.t , i.e which when evaluated on Eq. yields , hence:
If we perform eigendecomposition on the Jacobian matrix given by , we get the eigenvalues where and the corresponding eigenvectors .
Any change on the hidden state in the direction of a vector has the effect of multiplying the change with the eigenvalue associated with this eigenvector i.e .
The product of these Jacobians as seen in Eq. implies that subsequent time steps, will result in scaling the change with a factor equivalent to .
represents the eigenvalue raised to the power of the current time step .
Looking at the sequence , it is easy to see that the factor will end up dominating the ’s because this term grows exponentially fast as .
This means that if the largest eigenvalue then the gradient will vanish while if the value of , the gradient explodes.
Alternate intuition: Lets take a deeper look at the norms associated with these Jacobians:
In Eq. above, we set , the largest eigenvalue associated with as its upper bound, while largest eigenvalue associated with as its corresponding the upper bound.
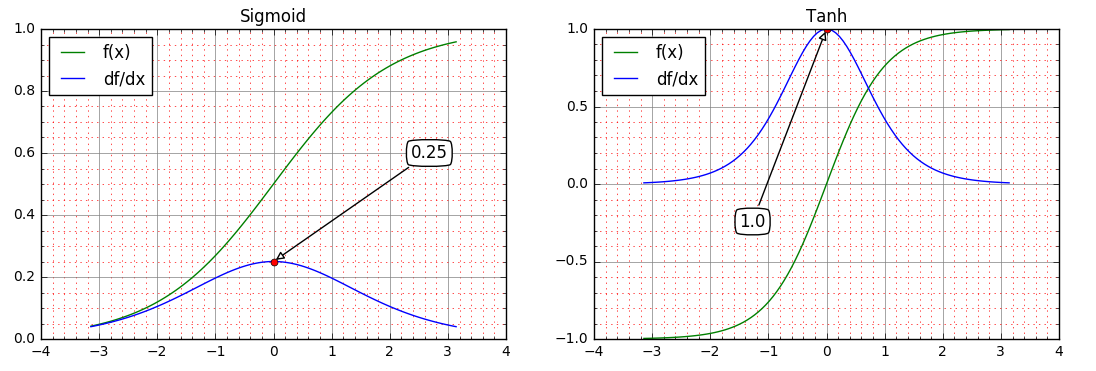
Depending on the activation function chosen for the model, the derivative in will be upper bounded by different values. For we have while for we have . These two are illustrated in the diagrams below:
The chosen upper bounds and end up being a constant term resulting from their product as shown in Eq. below:
The gradient , as seen in Eq. , is a product of Jacobian matrices that are multiplied many times, times to be precise in our case.
This relates well with Eq. above where the norm is essentially given by a constant term to the power as shown below:
As the sequence gets longer (i.e the distance between and increases), then the value of will determine if the gradient either gets very large (explodes) on gets very small (vanishes).
Since is associated with the leading eigenvalues of , the recursive product of Jacobian matrices as seen in Eq. makes it possible to influence the overall gradient in such a way that for the gradient tends to vanish while for the gradient tends to explode. This corresponds nicely with our earlier intuition involving .
These problems ultimately prevent the input at time step (past) to have any influence on the output at stage (present).
Proposed Solutions For Exploding Gradients
Truncated Backpropagation Through Time (TBPTT): This method sets up some maximum number of time steps is along which error can be propagated. This means in Eq. , we have where hence limiting the number of time steps factored into the overall error gradient during backpropagation.
This helps prevent the gradient from growing exponentially beyond steps. A major drawback with this method is that it sacrifices the ability to learn long-range dependencies beyond the limited range.
L1 and L2 Penalty On The Recurrent Weights : This method [1] uses regularization to ensures that the spectral radius of the does not exceed , which in itself is a sufficient condition for gradients not to explode.
The drawback here however is that the model is limited to a simple regime, all input has to die out exponentially fast in time. This method cannot be used to train a generator model and also sacrifices the ability to learn long-range dependencies.
Teacher Forcing: This method seeks to initialize the model in the right regime and the right region of space. It can be used in training of a generator model or models that work with unbounded memory lengths [2]. The drawback is that it requires the target to be defined at each time step.
Clipping Gradients: This method [1] seeks to rescale down gradients whenever they go beyond a given threshold. The gradients are prevented from exploding by rescaling them so that their norm is maintained at a value of less than or equal to the set threshold.
Let represent the gradient . If , then we set the value of to be:
The drawback here is that this method introduces an additional hyper-parameter; the threshold.
Echo State Networks: This method [1,8] works by not learning the weights between input to hidden and the weights between hidden to hidden . These weights are instead sampled from carefully chosen distributions. Training data is used to learn the weights between hidden to output .
The effect of this is that when weights in the recurrent connections are sampled so that their spectral radius is slightly less than 1, information fed into the model is held for a limited (small) number of time steps during the training process.
The drawback here is that these models loose the ability to learn long-range dependencies. This set up also has a negative effect on the vanishing gradient problem.
Proposed Solutions For Vanishing Gradients
Hessian Free Optimizer With Structural Dumping: This method [1,3] uses the Hessian which has the ability to rescale components in high dimensions independently since presumably, there is a high probability for long term components to be orthogonal to short term ones but in practice. However, one cannot guarantee that this property holds.
Structural dumping improves this by allowing the model to be more selective in the way it penalizes directions of change in parameter space, focusing on those that are more likely to lead to large changes in the hidden state sequence. This forces the change in state to be small, when parameter changes by some small value .
Leaky Integration Units: This method [1] forces a subset of the units to change slowly using the following state to state map:
When , the unit corresponds to a standard RNN. In [5] different values of were randomly sampled from , allowing some units to react quickly while others are forced to change slowly, but also propagate signals and gradients further in time hence increasing the time it takes for gradients to vanishing.
The drawback here is that since values chosen for then the gradients can still vanish while also still explode via .
Vanishing Gradient Regularization: This method [1] implements a regularizer that ensures during backpropagation, gradients neither increase or decrease much in magnitude. It does this by forcing the Jacobian matrices to preserve norm only in the relevant direction of the error .
The regularization term is as follows:
Long Short-Term Memory: This method makes use of sophisticated units the LSTMs [6] that implement gating mechanisms to help control the flow of information to and from the units. By shutting the gates, these units have the ability to create a linear self-loop through which allow information to flow for an indefinite amount of time thus overcoming the vanishing gradients problem.
Gated Recurrent Unit: This method makes use of units known as GRUs [7] which have only two gating units that that modulate the flow of information inside the unit thus making them less restrictive as compared to the LSTMs, while still having the ability to allow information to flow for an indefinite amount of time hence overcoming the vanishing gradients problem.
Orthogonal initialization: This method makes use of a well known property of orthogonal matrices: “all the eigenvalues of an orthogonal matrix have absolute value ”.
Initialization of weights using matrices that are orthogonal results in weight matrices that have the leading eigenvalue with an absolute value . Looking at Eq. it is easy to conclude that in the products of the Jacobians involved, the leading eigenvalue will not have an adverse effect on the overall gradient value in the long run since as
This makes it possible to avoid both the vanishing and exploding gradient problem using this orthogonal initialization of weights. This method [9] however is not used in isolation and is often combined with other more advanced architectures like LSTMs to achieve optimal results.
Conclusions
In this article we went through the intuition behind the vanishing and exploding gradient problems. The values of the largest eigenvalue have a direct influence in the way the gradient behaves eventually. causes the gradients to vanish while caused the gradients to explode.
This leads us to the fact would avoid both the vanishing and exploding gradient problems and although it is not as straightforward as it seems. This fact however has been used as the intuition behind creating most of the proposed solutions.
The proposed solutions are discussed here in brief but with some key references that the readers would find useful in obtain a greater understanding of how they work. Feel free to leave questions or feedback in the comments section.
References
- Pascanu, Razvan; Mikolov, Tomas; Bengio, Yoshua (2012) On the difficulty of training Recurrent Neural Networks [PDF]
- Doya, K. (1993). Bifurcations of recurrent neural networks in gradient descent learning. IEEE Transactions on Neural Networks, 1, 75–80. [PDF]
- Martens, J. and Sutskever, I. (2011). Learning recurrent neural networks with Hessian-free optimization. In Proc. ICML’2011 . ACM. [PDF]
- Jaeger, H., Lukosevicius, M., Popovici, D., and Siewert, U. (2007). Optimization and applications of echo state networks with leaky- integrator neurons. Neural Networks, 20(3), 335–352. [PDF]
- Yoshua Bengio, Nicolas Boulanger-Lewandowski, Razvan Pascanu, Advances in Optimizing Recurrent Networks arXiv report 1212.0901, 2012. [PDF]
- Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8):1735–1780. [PDF]
- Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proc. EMNLP, pages 1724–1734. ACL, 2014 [PDF]
- Lukoˇseviˇcius, M. and Jaeger, H. (2009). Reservoir computing approaches to recurrent neural network training. Computer Science Review, 3(3), 127–149. [PDF]
- Mikael Henaff, Arthur Szlam, Yann LeCun Recurrent Orthogonal Networks and Long-Memory Tasks. 2016 [PDF]