Initialization Of Deep Networks Case of Rectifiers
Jefkine, 8 August 2016Introduction
Recent success in deep networks can be credited to the use of non-saturated activation function Rectified Linear unit (RReLu) which has replaced its saturated counterpart (e.g. sigmoid, tanh). Benefits associated with the ReLu activation function include:
- Ability to mitigate the exploding or vanishing gradient problem; this largely due to the fact that for all inputs into the activation function of values grater than , the gradient is always (constant gradient)
- The constant gradient of ReLu activations results in faster learning. This helps expedite convergence of the training procedure yielding better better solutions than sigmoidlike units
- Unlike the sigmoidlike units (such as sigmoid or tanh activations) ReLu activations does not involve computing of an an exponent which is a factor that results to a faster training and evaluation times.
- Producing sparse representations with true zeros. All inputs into the activation function of values less than or equal to , results in an output value of . Sparse representations are considered more valuable
Xavier and Bengio (2010) [2] had earlier on proposed the “Xavier” initialization, a method whose derivation was based on the assumption that the activations are linear. This assumption however is invalid for ReLu and PReLu. He, Kaiming, et al. 2015 [1] later on derived a robust initialization method that particularly considers the rectifier nonlinearities.
In this article we discuss the algorithm put forward by He, Kaiming, et al. 2015 [1].
Notation
- is the side length of a convolutional kernel. (also the spatial filter size of the layer)
- is the channel number. (also input channel)
- is the number of connections of a response ()
- is the co-located pixels in inputs channels. ()
- is the matrix where is the total number number of filters. Every row of i.e represents the weights of a filter. ()
- is the vector of biases.
- is the response pixel of the output map
- is used to index the layers
- is the activation function
Forward Propagation Case
Considerations made here include:
- The initialized elements in be mutually independent and share the same distribution.
- The elements in are mutually independent and share the same distribution.
- and are independent of each other.
The variance of can be given by: $$ \begin{align} Var[y_l] &= n_lVar[w_lx_l], \tag 1 \end{align} $$
where represent random variables of each element in . Let have a zero mean, then the variance of the product of independent variables gives us: $$ \begin{align} Var[y_l] &= n_lVar[w_l]E[x^2_l]. \tag 2 \end{align} $$
Lets look at how the Eqn. above is arrived at:-
For random variables and , independent of each other, we can use basic properties of expectation to show that: $$ \begin{align} Var[w_lx_l] &= E[w^2_l]E[x^2_l] - \overbrace{ \left[ E[x_l]\right]^2 \left[ E[w_l]\right]^2 }^{ \bigstar } , \tag {A} \end{align} $$
From Eqn. above, we let have a zero mean . This means that in Eqn. , evaluates to zero. We are then left with: $$ \begin{align} Var[w_lx_l] &= E[w^2_l]E[x^2_l], \tag {B} \end{align} $$
Using the formula for variance and the fact that we come to the conclusion that .
With this conclusion we can replace in Eqn. with to obtain the following Eqn.: $$ \begin{align} Var[w_lx_l] &= Var[w_l]E[x^2_l], \tag {C} \end{align} $$
By substituting Eqn. into Eqn. we obtain: $$ \begin{align} Var[y_l] &= n_lVar[w_l]E[x^2_l]. \tag 2 \end{align} $$
In Eqn. it is well worth noting that is the expectation of the square of and cannot resolve to i.e as we did above for unless has zero mean.
The effect of ReLu activation is such that and thus it does not have zero mean. For this reason the conclusion here is different compared to the initialization style in [2].
We can also observe here that despite the mean of i.e being non zero, the product of the two means and will lead to a zero mean since as shown in the Eqn. below: $$ \begin{align} E[y_l] &= E[w_lx_l] = E[x_l]E[w_l] = 0. \end{align} $$
If we let have a symmetric distribution around zero and , then from our observation above has zero mean and a symmetric distribution around zero. This leads to when is ReLu. Putting this in Eqn. , we obtain: $$ \begin{align} Var[y_l] &= n_lVar[w_l]\frac{1}{2}Var[y_{l-1}]. \tag 3 \end{align} $$
With layers put together, we have: $$ \begin{align} Var[y_L] &= Var[y_1]\left( \prod_{l=1}^L \frac{1}{2}n_lVar[w_l] \right). \tag 4 \end{align} $$
The product in Eqn. is key to the initialization design.
Lets take some time to explain the effect of ReLu activation as seen in Eqn. .
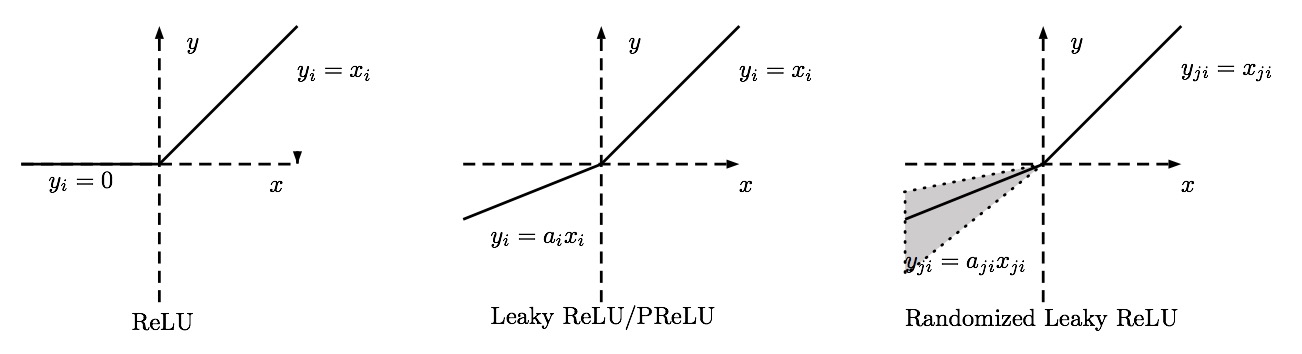
For the family of rectified linear (ReL) shown illustrated in the diagram above, we have a generic activation function defined as follows:
In the activation function above, is the input of the nonlinear activation on the th channel, and is the coefficient controlling the slope of the negative part. in indicates that we allow the nonlinear activation to vary on different channels.
The variations of rectified linear (ReL) take the following forms:
- ReLu: obtained when . The resultant activation function is of the form
- PReLu: Parametric ReLu - obtained when is a learnable parameter. The resultant activation function is of the form
- LReLu: Leaky ReLu - obtained when i.e when is a small and fixed value [3]. The resultant activation function is of the form
- RReLu: Randomized Leaky ReLu - the randomized version of leaky ReLu, obtained when is a random number sampled from a uniform distribution i.e . See [2].
Rectifier activation function is simply a threshold at zero hence allowing the network to easily obtain sparse representations. For example, after uniform initialization of the weights, around of hidden units continuous output values are real zeros, and this fraction can easily increase with sparsity-inducing regularization [5].
Take signal (visualize the signal represented on a bi-dimensional space ). Applying the rectifier activation function to this signal i.e where is ReLu results in a scenario where signals existing in regions where are squashed to , while those existing in regions where remain unchanged.
The ReLu effect results in “aggressive data compression” where information is lost (replaced by real zeros values). A remedy for this would be the PReLu and LReLu implementations which provides an axle shift that adds a slope to the negative section ensuring from the data some information is retained rather than reduced to zero. Both PReLu and LReLu represented by variations of , make use of the factor which serves as the component used to retain some information.
Using ReLu activation function function therefore, only the positive half axis values are obtained hence:
Putting this in Eqn. , we obtain our Eqn. as above:
Note that a proper initialization method should avoid reducing and magnifying the magnitudes of input signals exponentially. For this reason we expect the product in Eqn. to take a proper scalar (e.g., 1). This leads to: $$ \begin{align} \frac{1}{2}n_lVar[w_l] &= 1, \quad \forall l \tag 7 \end{align} $$
From Eqn. above, we can conclude that: $$ \begin{align} Var[w_l] = \frac{2}{n_l} \implies \text{standard deviation (std)} = \sqrt{\frac{2}{n_l}} \end{align} $$
The initialization according to [1] is a zero-mean Gaussian distribution whose standard deviation (std) is . The bias is initialized to zero. The initialization distribution therefore is of the form: $$ \begin{align} W_l \sim \mathcal N \left({\Large 0}, \sqrt{\frac{2}{n_l}} \right) \,\text{and} \,\mathbf{b} = 0. \end{align} $$
From Eqn. , we can observe that for the first layer , the variance of weights is given by because there is no ReLu applied on the input signal. However, the factor of a single layer does not make the overall product exponentially large or small and as such we adopt Eqn. in the first layer for simplicity.
Backward Propagation Case
For back-propagation, the gradient of the conv-layer is computed by: $$ \begin{align} \Delta{\mathbf{x}_l} &= W_l\Delta{\mathbf{y}_l}. \tag{8} \end{align} $$
Notation
- is the gradient
- is the gradient
- is represented by by pixels in channels and is thus reshaped into by vector i.e .
- is given by also note that .
- is a matrix where filters are arranged in the back-propagation way. Also and can be reshaped from each other.
- is a vector representing the gradient at a pixel of this layer.
Assumptions made here include:
- Assume that and are independent of each other then has zero mean for all , when is initialized by a symmetric distribution around zero.
- Assume that and are independent of each other
In back-propagation we have where is the derivative of . For the ReLu case is either zero or one with their probabilities being equal i.e and .
Lets build on from some definition here; for a discrete case, the expected value of a discrete random variable, X, is found by multiplying each X-value by its probability and then summing over all values of the random variable. That is, if X is discrete, $$ \begin{align} E[X] &= \sum_{\text{all}\,x} xp(x) \end{align} $$
The expectation of then: $$ \begin{align} E[f’(y_l)] &= (0)\frac{1}{2} + (1)\frac{1}{2} = \frac{1}{2} \tag{9} \end{align} $$
With the independence of and , we can show that: The expectation of then: $$ \begin{align} E[\Delta{y_{l}}] &= E[f’(y_l)\Delta{x_{l+1}}] = E[f’(y_l)]E[\Delta{x_{l+1}}] \tag{10} \end{align} $$
Substituting results in Eqn. into Eqn. we obtain: $$ \begin{align} E[\Delta{y_{l}}] &= \frac{1}{2}E[\Delta{x_{l+1}}] = 0 \tag{11} \end{align} $$
In Eqn. has zero mean for all which gives us the result zero. With this we can show that using the formula of variance as follows:
Again with the assumption that has zero mean for all , we show can that the variance of product of two independent variables and to be
From the values of we can observe that and meaning .
This means that . Using this result in Eqn. we obtain:
Using the formula for variance and yet again the assumption that has zero mean for all , we show can that :
Substituting this result in Eqn. we obtain: $$ \begin{align} E[(\Delta{y_{l}})^2] &= Var[\Delta{y_{l}}] = \frac{1}{2}E[(\Delta{x_{l+1}})^2] \tag{15} \end{align} $$
The variance of Eqn. can be shown to be:
The scalar in both Eqn. and Eqn. is the result of ReLu, though the derivations are different. With layers put together, we have: $$ \begin{align} Var[\Delta{x_2}] &= Var[\Delta{x_{L+1}}]\left( \prod_{l=2}^L \frac{1}{2}\hat{n}_lVar[w_l] \right) \tag{17} \end{align} $$
Considering a sufficient condition that the gradient is not exponentially large/small: $$ \begin{align} \frac{1}{2}\hat{n}_lVar[w_l] &= 1, \quad \forall{l} \tag{18} \end{align} $$
The only difference between Eqn. and Eqn. is that while . Eqn. results in a zero-mean Gaussian distribution whose standard deviation (std) is . The initialization distribution therefore is of the form: $$ \begin{align} W_l \sim \mathcal N \left({\Large 0}, \sqrt{\frac{2}{\hat{n}_l}} \right) \end{align} $$
For the layer , we need not compute because it represents the image domain. We adopt Eqn. for the first layer for the same reason as the forward propagation case - the factor of a single layer does not make the overall product exponentially large or small.
It is noted that use of either Eqn. or Eqn. alone is sufficient. For example, if we use Eqn., then in Eqn. the product , and in Eqn. the product , which is not a diminishing number in common network designs. This means that if the initialization properly scales the backward signal, then this is also the case for the forward signal; and vice versa.
For initialization in the PReLu case, it is easy to show that Eqn. becomes: $$ \begin{align} \frac{1}{2}(1+a^2)n_lVar[w_l] &= 1, \tag {19} \end{align} $$
Where is the initialized value of the coefficients. If , it becomes the ReLu case; if , it becomes the linear case; same as [2]. Similarly, Eqn. becomes: $$ \begin{align} \frac{1}{2}(1+a^2)\hat{n}_lVar[w_l] &= 1, \tag {20} \end{align} $$
Applications
The initialization routines derived here, more famously known as “Kaiming Initialization” have been successfully applied in various deep learning libraries. Below we shall look at Keras a minimalist, highly modular neural networks library, written in Python and capable of running on top of either TensorFlow or Theano.
The initialization routine here is named “he_” following the name of one of the authors Kaiming He [1]. In the code snippet below, he_normal is the implementation of initialization based on Gaussian distribution while he_uniform is the equivalent implementation of initialization based on Uniform distribution
def get_fans(shape):
fan_in = shape[0] if len(shape) == 2 else np.prod(shape[1:])
fan_out = shape[1] if len(shape) == 2 else shape[0]
return fan_in, fan_out
def he_normal(shape, name=None):
fan_in, fan_out = get_fans(shape)
s = np.sqrt(2. / fan_in)
return normal(shape, s, name=name)
def he_uniform(shape, name=None):
fan_in, fan_out = get_fans(shape)
s = np.sqrt(6. / fan_in)
return uniform(shape, s, name=name)References
- He, Kaiming, et al. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.” Proceedings of the IEEE International Conference on Computer Vision. 2015. [PDF]
- Glorot Xavier, and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks.” Aistats. Vol. 9. 2010. [PDF]
- A. L. Maas, A. Y. Hannun, and A. Y. Ng. “Rectifier nonlinearities improve neural network acoustic models.” In ICML, 2013. [PDF]
- Xu, Bing, et al. “Empirical Evaluation of Rectified Activations in Convolution Network.” [PDF]
- Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. “Deep Sparse Rectifier Neural Networks.” Aistats. Vol. 15. No. 106. 2011. [PDF]