Backpropagation In Convolutional Neural Networks
Jefkine, 5 September 2016Introduction
Convolutional neural networks (CNNs) are a biologically-inspired variation of the multilayer perceptrons (MLPs). Neurons in CNNs share weights unlike in MLPs where each neuron has a separate weight vector. This sharing of weights ends up reducing the overall number of trainable weights hence introducing sparsity.
Utilizing the weights sharing strategy, neurons are able to perform convolutions on the data with the convolution filter being formed by the weights. This is then followed by a pooling operation which as a form of non-linear down-sampling, progressively reduces the spatial size of the representation thus reducing the amount of computation and parameters in the network.
Existing between the convolution and the pooling layer is an activation function such as the ReLu layer; a non-saturating activation is applied element-wise, i.e. thresholding at zero. After several convolutional and pooling layers, the image size (feature map size) is reduced and more complex features are extracted.
Eventually with a small enough feature map, the contents are squashed into a one dimension vector and fed into a fully-connected MLP for processing. The last layer of this fully-connected MLP seen as the output, is a loss layer which is used to specify how the network training penalizes the deviation between the predicted and true labels.
Before we begin lets take look at the mathematical definitions of convolution and cross-correlation:
Cross-correlation
Given an input image and a filter (kernel) of dimensions , the cross-correlation operation is given by:
Convolution
Given an input image and a filter (kernel) of dimensions , the convolution operation is given by:
From Eq. it is easy to see that convolution is the same as cross-correlation with a flipped kernel i.e: for a kernel where .
Convolution Neural Networks - CNNs
CNNs consists of convolutional layers which are characterized by an input map , a bank of filters and biases .
In the case of images, we could have as input an image with height , width and channels (red, blue and green) such that . Subsequently for a bank of filters we have and biases , one for each filter.
The output from this convolution procedure is as follows:
The convolution operation carried out here is the same as cross-correlation, except that the kernel is “flipped” (horizontally and vertically).
For the purposes of simplicity we shall use the case where the input image is grayscale i.e single channel . The Eq. will be transformed to:
Notation
To help us explore the forward and backpropagation, we shall make use of the following notation:
- is the layer where is the first layer and is the last layer.
- Input is of dimension and has by as the iterators
- Filter or kernel is of dimension has by as the iterators
- is the weight matrix connecting neurons of layer with neurons of layer .
- is the bias unit at layer .
- is the convolved input vector at layer plus the bias represented as $$ \begin{align} x_{i,j}^l = \sum_{m}\sum_{n} w_{m,n}^l o_{i + m,j + n}^{l-1} + b^l \end{align} $$
- is the output vector at layer given by $$ \begin{align} o_{i,j}^l = f(x_{i,j}^{l}) \end{align} $$
- is the activation function. Application of the activation layer to the convolved input vector at layer is given by
Foward Propagation
To perform a convolution operation, the kernel is flipped and slid across the input feature map in equal and finite strides. At each location, the product between each element of the kernel and the input input feature map element it overlaps is computed and the results summed up to obtain the output at that current location.
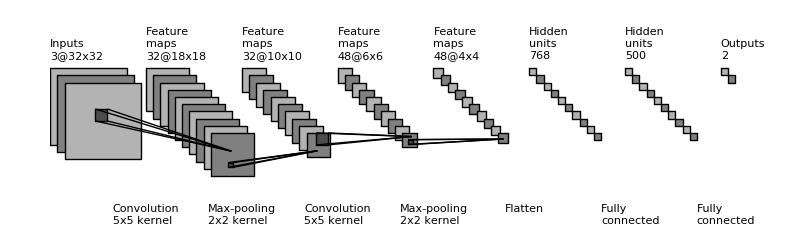
This procedure is repeated using different kernels to form as many output feature maps as desired. The concept of weight sharing is used as demonstrated in the diagram below:
Units in convolutional layer illustrated above have receptive fields of size 4 in the input feature map and are thus only connected to 4 adjacent neurons in the input layer. This is the idea of sparse connectivity in CNNs where there exists local connectivity pattern between neurons in adjacent layers.
The color codes of the weights joining the input layer to the convolutional layer show how the kernel weights are distributed (shared) amongst neurons in the adjacent layers. Weights of the same color are constrained to be identical.
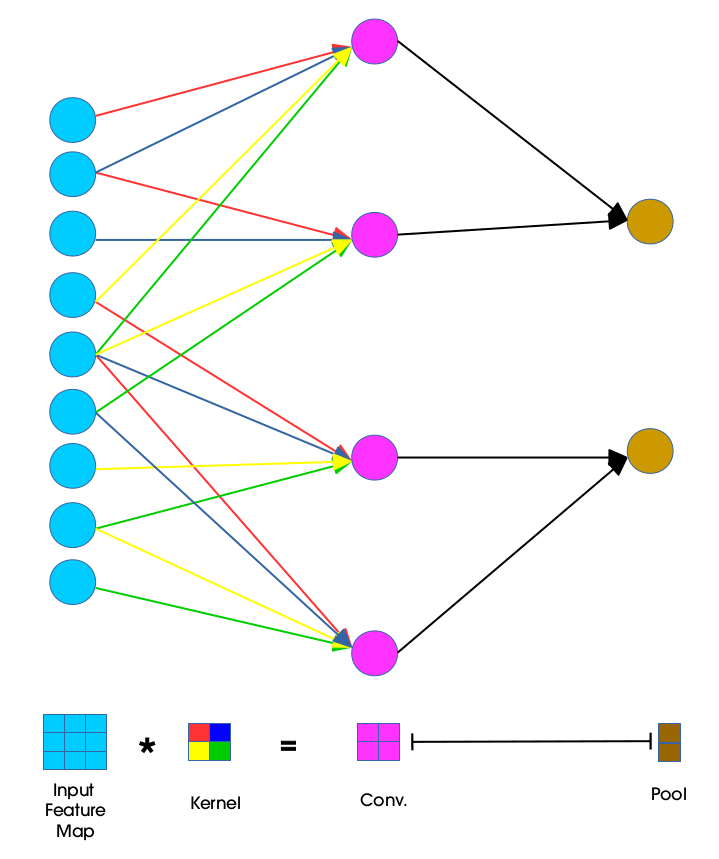
The convolution process here is usually expressed as a cross-correlation but with a flipped kernel. In the diagram below we illustrate a kernel that has been flipped both horizontally and vertically:

The convolution equation of the input at layer is given by:
This is illustrated below:
Error
For a total of predictions, the predicted network outputs and their corresponding targeted values the the mean squared error is given by: $$ \begin{align} E &= \frac{1}{2}\sum_{p} \left(t_p - y_p \right)^2 \tag {9} \end{align} $$
Learning will be achieved by adjusting the weights such that is as close as possible or equals to corresponding . In the classical backpropagation algorithm, the weights are changed according to the gradient descent direction of an error surface .
Backpropagation
For backpropagation there are two updates performed, for the weights and the deltas. Lets begin with the weight update.
We are looking to compute which can be interpreted as the measurement of how the change in a single pixel in the weight kernel affects the loss function .
![]()
During forward propagation, the convolution operation ensures that the yellow pixel in the weight kernel makes a contribution in all the products (between each element of the weight kernel and the input feature map element it overlaps). This means that pixel will eventually affect all the elements in the output feature map.
Convolution between the input feature map of dimension and the weight kernel of dimension produces an output feature map of size by . The gradient component for the individual weights can be obtained by applying the chain rule in the following way:
In Eq. is equivalent to and expanding this part of the equation gives us:
Further expanding the summations in Eq. and taking the partial derivatives for all the components results in zero values for all except the components where and in as follows:
Substituting Eq. in Eq. gives us the following results:
The dual summation in Eq. is as a result of weight sharing in the network (same weight kernel is slid over all of the input feature map during convolution). The summations represents a collection of all the gradients coming from all the outputs in layer .
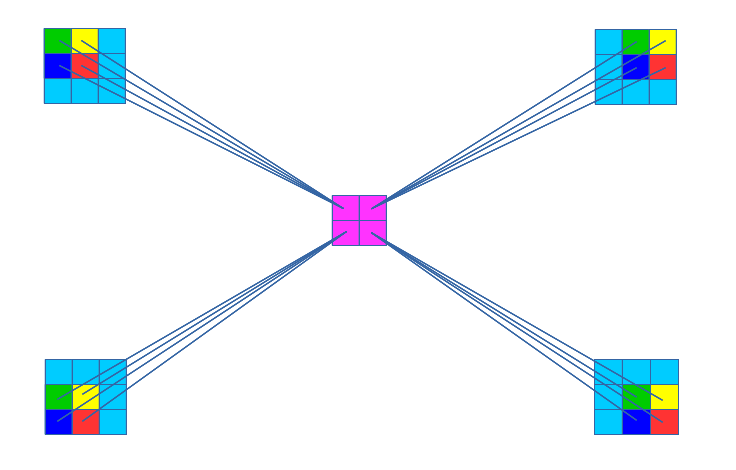
Obtaining gradients w.r.t to the filter maps, we have a cross-correlation which is transformed to a convolution by “flipping” the delta matrix (horizontally and vertically) the same way we flipped the filters during the forward propagation.
An illustration of the flipped delta matrix is shown below:

The diagram below shows gradients generated during backpropagation:
The convolution operation used to obtain the new set of weights as is shown below:
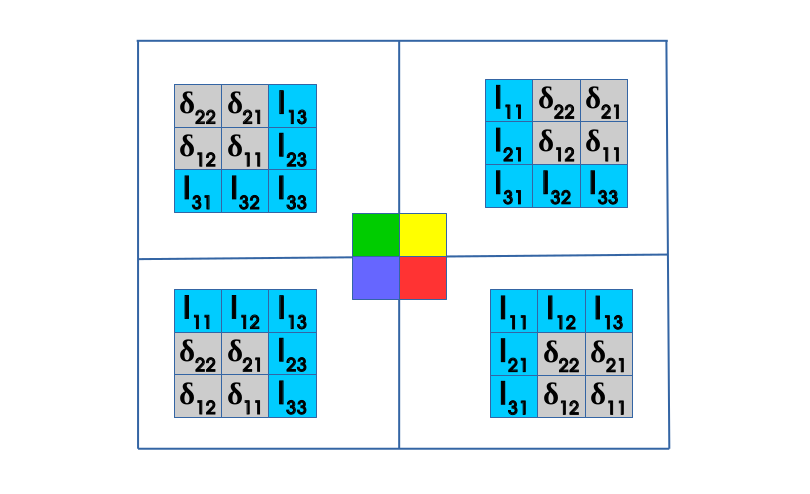
During the reconstruction process, the deltas are used. These deltas are provided by an equation of the form:
At this point we are looking to compute which can be interpreted as the measurement of how the change in a single pixel in the input feature map affects the loss function .
![]()
From the diagram above, we can see that region in the output affected by pixel from the input is the region in the output bounded by the dashed lines where the top left corner pixel is given by and the bottom right corner pixel is given by .
Using chain rule and introducing sums give us the following equation:
in the summation above represents the output region bounded by dashed lines and is composed of pixels in the output that are affected by the single pixel in the input feature map. A more formal way of representing Eq. is:
In the region , the height ranges from to and width to . These two can simply be represented by and in the summation since the iterators and exists in the following similar ranges from and .
In Eq. is equivalent to and expanding this part of the equation gives us:
Further expanding the summation in Eq. and taking the partial derivatives for all the components results in zero values for all except the components where and so that becomes and becomes in the relevant part of the expanded summation as follows:
Substituting Eq. in Eq. gives us the following results:
For backpropagation, we make use of the flipped kernel and as a result we will now have a convolution that is expressed as a cross-correlation with a flipped kernel:
Pooling Layer
The function of the pooling layer is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network, and hence to also control overfitting. No learning takes place on the pooling layers [2].
Pooling units are obtained using functions like max-pooling, average pooling and even L2-norm pooling. At the pooling layer, forward propagation results in an pooling block being reduced to a single value - value of the “winning unit”. Backpropagation of the pooling layer then computes the error which is acquired by this single value “winning unit”.
To keep track of the “winning unit” its index noted during the forward pass and used for gradient routing during backpropagation. Gradient routing is done in the following ways:
- Max-pooling - the error is just assigned to where it comes from - the “winning unit” because other units in the previous layer’s pooling blocks did not contribute to it hence all the other assigned values of zero
- Average pooling - the error is multiplied by and assigned to the whole pooling block (all units get this same value).
Conclusion
Convolutional neural networks employ a weight sharing strategy that leads to a significant reduction in the number of parameters that have to be learned. The presence of larger receptive field sizes of neurons in successive convolutional layers coupled with the presence of pooling layers also lead to translation invariance. As we have observed the derivations of forward and backward propagations will differ depending on what layer we are propagating through.
References
- Dumoulin, Vincent, and Francesco Visin. “A guide to convolution arithmetic for deep learning.” stat 1050 (2016): 23. [PDF]
- LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W.,Jackel, L.D.: Backpropagation applied to handwritten zip code recognition. Neural computation 1(4), 541–551 (1989)
- Wikipedia page on Convolutional neural network
- Convolutional Neural Networks (LeNet) deeplearning.net
- Convolutional Neural Networks UFLDL Tutorial